Лекция 1. C.
Scratch vs. C
Scratch помог нам изучить основные концепции программирования и теперь мы можем применить их в настоящем языке программирования, Cи.
Помните, на прошлой неделе, когда мы хотели запустить наше приложение в Scratch, мы знали, что нам нужно было использовать блок с названием когда щелкнут по зеленому флажку.
Наш пример реализации блока сказать: hello,world можно реализовать в Cи следующим образом:
#include <stdio.h>
int main(void)
{
printf("hello, world\n");
}
printf похож на блок Scratch’a сказать, и он отобразит на экране всё, что будет внутри его кавычек.
Вот так мы начинаем наше знакомство с синтаксисом, двойные кавычки и точка с запятой - всё потихоньку.
В Scratch’e блок сказать представлял из себя функцию, которая принимала аргумент или параметр. В Си это можно сделать как-то так:
printf("hello, world\n");
Управляющий символ \n создает новую строку - все равно, что нажать на Enter, находясь в блокноте.
В случае с циклами, в Scratch у нас есть блок всегда, который позволяет бесконечно повторять какое-то действие. В Си мы будем делать так:
while (true)
{
printf("hello, world\n");
}
Выражение, находящееся внутри фигурных скобок, будет выполняться снова и снова пока(while) условие, находящееся внутри скобок, будет истиной, и так как истина (true) всегда будет истиной, цикл никогда не завершится, бесконечно повторяя себя.
Чтобы цикл имел определенное количество повторов, надо будет немного усложнить код:
for (int i = 0; i < 50; i++)
{
printf("hello, world\n");
}
Мы вернемся к этому циклу чуть позже, а пока достаточно знать, что слово for или “для”, является особым, обозначающим начало цикла.
В Scratch, мы использовали блоки задать [i] значение [0] для представления переменных, способные хранить значения. В Си мы сделаем это так:
int i = 0;
int обозначает integer, в нем мы создаем переменную для хранения целых чисел. i - это название нашей новой переменной, и 0 - это значение, которое мы ему присвоим.
Наконец, точка с запятой обозначает завершение данного выражения.
Булево выражения по сути своей являются вопросами, которые дают один результат: истину (true) или ложь (false). В Scratch’e это выглядело как i < 50 или i меньше 50. В Си все также просто :
i < 50
С x < y тоже самое. Выражение одинаковое как в Scratch, так и в Си, до тех пор пока оба x и y будут представлять из себя созданные нами переменные, которым были присвоены значения.
Также можно использовать условия, позволяющие выбрать одну из нескольких дорог. В Scratch’e мы показывали что-то похожее на это:
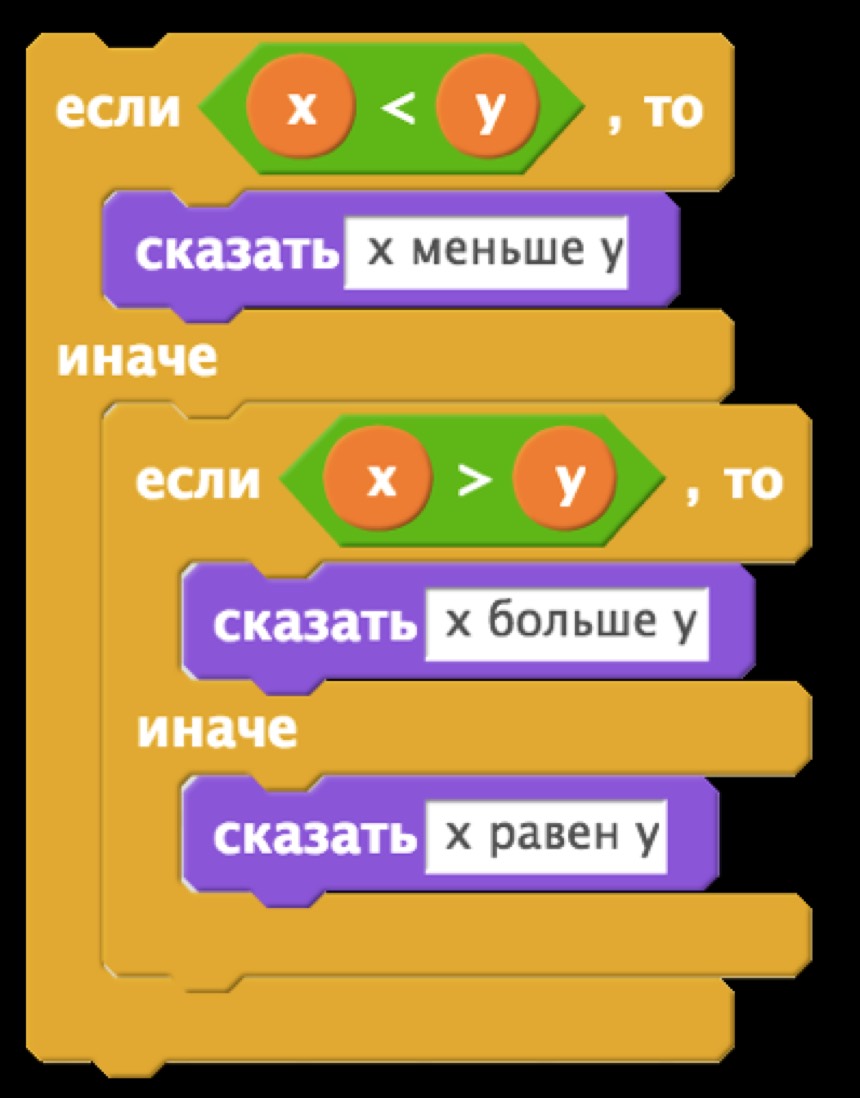
Всё это можно намного легче выразить в Cи:
if (x < y)
{
printf("x меньше y\n");
}
else if (x > y)
{
printf("x больше y\n");
}
else
{
printf("x равен y\n");
}
Scratch не поленился показать нам списки, в которых мы могли хранить сразу несколько значений. В Си тоже самое проделывают массивы, в которых мы можем упорядоченно хранить огромное число элементов.
В прошлый раз Scratch представил нам такой блок как элемент (1) из [argv], который доставал первый элемент из списка под названием argv. В Си (мы начинаем считать начиная с 0, т.к. это самое маленькое неотрицательное число) мы гораздо легче сможем проделать вышеприведенную операцию argv[0].
hello, C
Вернемся к нашему примеру:
#include <stdio.h>
int main(void)
{
printf("hello, world\n");
}
main представляет из себя блок когда щелкнут по зеленой кнопке, и помечает основной (main) кусочек кода, который будет выполняться при любых условиях.
Этот код, читабельный для “обычных” людей (или понятный “людям”), необходимо перевести в машинный код, который выглядит как-то так:
01111111 01000101 01001100 01000110 00000010 00000001 00000001 00000000
00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
00000010 00000000 00111110 00000000 00000001 00000000 00000000 00000000
10110000 00000101 01000000 00000000 00000000 00000000 00000000 00000000
01000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
11010000 00010011 00000000 00000000 00000000 00000000 00000000 00000000
00000000 00000000 00000000 00000000 01000000 00000000 00111000 00000000
00001001 00000000 01000000 00000000 00100100 00000000 00100001 00000000
00000110 00000000 00000000 00000000 00000101 00000000 00000000 00000000
01000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
01000000 00000000 01000000 00000000 00000000 00000000 00000000 00000000
01000000 00000000 01000000 00000000 00000000 00000000 00000000 00000000
11111000 00000001 00000000 00000000 00000000 00000000 00000000 00000000
11111000 00000001 00000000 00000000 00000000 00000000 00000000 00000000
00001000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
00000011 00000000 00000000 00000000 00000100 00000000 00000000 00000000
00111000 00000010 00000000 00000000 00000000 00000000 00000000 00000000
00111000 00000010 01000000 00000000 00000000 00000000 00000000 00000000
00111000 00000010 01000000 00000000 00000000 00000000 00000000 00000000
00011100 00000000 00000000 00000000 00000000 00000000 00000000 00000000
...
Кто бы мог подумать…
Нельзя забывать: как бы мы не пытались убежать от той простой истины, что компьютер работает только с бинарными числами, 0ми и 1ми, каждая такая последовательность (шаблон) 0ей и 1иц представляет из себя специальные инструкции CPU (процессора - центрального процессорного устройства компьютера). Одна последовательность 0 и 1 будет обозначать “выведи это на экран”, другая последовательность - “сложи эти два числа” или любую другую операцию из огромного числа возможных.
Нам не нужно самим писать все эти числа, т.к. есть программы compilers (компиляторы), которые берут код, написанный на понятном для людей языке Си (source code или исходный код), и переводит его в машинный.
У каждого из нас установлены на рабочем компьютере, мало отличающимися друг от друга, различные операционные системы, такие как macOS, Windows или другие. Поэтому, чтобы избежать всевозможных несовместимостей, мы будем использовать “облачную” систему CS50 IDE.
Что это означает? Хотелось бы сказать “не ваше дело” и “просто поверьте на слово и хватит всем интересоваться”, но черт с вами… Это среда разработки, а точнее веб-среда разработки основанная на платформе Cloud9, позволяющая установить и настроить программное обеспечение, к которому потом может получить доступ огромное количество пользователей, у каждого из которых будет своя индивидуальная среда.
Заходим на страницу сайта, создаем бесплатный аккаунт и перед вами будет:
Теперь у нас есть файл под названием hello.c. Привыкайте к тому, что файлы с исходным кодом написанным на Си, имеют расширение .c. Мы также напишем в редакторе:
#include <stdio.h>
int main(void)
{
printf("hello, world\n");
}
Мы привыкли запускать программы на своих компьютерах двойным нажатием по иконке. Облачные компьютеры, которыми мы теперь будем пользоваться, используют операционную систему linux, которая часто поставляется с графическим интерфейсом (GUI), но больше она известна своим интерфейсом командной строки - ее мы и будем использовать.
В нижней части нашего рабочего пространства мы напишем clang hello.c:
~/workspace/ $ clang hello.c
clang (в языке программирования Си) является компилятором, которого мы просим скомпилировать наш файл hello.c.
~/workspace/ обозначает, что мы находимся в папке под названием workspace, в которой находится hello.c (в этом можно удостовериться, посмотрев на список файлов в левой панели). Знак $ дает нам знать, что мы можем начинать писать команды.
После того как мы нажмем enter, покажется что ничего не произошло:
~/workspace/ $ clang hello.c
~/workspace/ $
Но в итоге clang создаст программу, присвоив ей по-умолчанию имя a.out. Давайте её запустим:
~/workspace/ $ ./a.out
hello, world
~/workspace/ $
Все отобразилось так, как мы и хотели. Также наш курсор переместился на новую строку. Вспомните, что в нашем исходном коде был дополнительный символ \n, который и создал эту новую строку.
Если бы мы его убрали из нашего исходного кода, сохранили, повторно скомпилировали, а затем и запустили - мы увидели бы следующее:
~/workspace/ $ clang hello.c
~/workspace/ $ ./a.out
hello, world~/workspace/ $
Программа бы запустилась, но без новой строки.
Поэтому мы оставим все как есть. И помните - каждый раз, когда мы хоть что-то меняем в исходном коде, его обязательно нужно повторно скомпилировать.
Мы еще можем попросить нашего нового друга clang‘a, скомпилировать программу, присвоив ей красивое имя. Нам помогут аргументы (по-другому флаги или переключатели) командной строки:
~/workspace/ $ clang -o hello hello.c
Итак, по середине мы добавили -o для данных на выходе (т.е. для создаваемой программы), указав, что хотим присвоить им название hello.
Теперь можно нажать enter и запустить ./hello.
Но как-то слишком все это выглядит обременяющим, не говоря уже о том, что чем тяжелее будет наша программа, тем больше аргументов нам придется использовать. Поэтому гениальные (ленивые) разработчики создали программу make, которую мы и будем в дальнейшем использовать.
Но сперва кое-какие поправки. Мы исполним команду ls, чтобы показать все файлы нашей директории (папки) workspace :
~/workspace/ $ ls
a.out* hello* hello.c
Она выводит на экран список файлов, которые мы можем увидеть на левой стороне нашего рабочего пространства. Но на этом мы не остановимся:
~/workspace/ $ rm a.out
Данная команда rm удаляет файл. Она просит нас подтвердить удаление - и как же тут отказать, пишем y (означает “yes” или “да”).
Выполнимые программы, т.е. те, что мы можем запустить, тоже выводятся командой ls, помеченные * (звездочкой) и особым цветом.
Давайте воспользуемся make:
~/workspace/ $ make hello
Эта программа создаст запускаемый исполняемый файл с названием hello, который формируется из файла с исходным кодом hello.c. Все это она проделывает, использую только одно слово (hello).
После нажатия enter мы увидим длинную команду начинающуюся с clang. Тут огромное количество дополнительных аргументов (опций, которые нам пригодятся в будущем), но сейчас для нас самое главное то, что мы опять получили файл с названием hello, который мы можем запустить.
Другая командная строка linux, ой неправильно, остальные команды:
-
cdchange directory (изменить папку), так мы перемещаемся по папкам -
lsуже видели -
mkdirmake directory (создать папку), создает папку -
rmremove (удалить), удаляет файл -
rmdirremove directory (удалить папку), удаляет папку
Библиотека CS50
Давайте создадим больше интересных программ.
Чтобы принимать вводимые пользователем данные, мы создали для вас несколько функций:
-
get_char -
get_double -
get_float -
get_int -
get_long_long -
get_string
Создадим файл string.c (string или строка, представляет из себя последовательность символов):
#include <cs50.h>
#include <stdio.h>
int main(void)
{
string name = get_string();
printf("hello, %s\n", name);
}
Первые строчки кода включают библиотеки или группы написанных кем-то функций, которые мы можем использовать в нашем коде. Библиотека cs50.h содержит в себе приведенные выше функции, а stdio.h (Standard Input and Output/Стандартный Ввод и Вывод) содержит основные функции Си, как например printf. Библиотека cs50.h также дает нам возможность пользоваться особым типом переменной под названием string, которого нету в Си.
В нашей функции main мы сперва создадим переменную string под названием name и используем функцию get_string. Нам нужно закончить функцию (), т.к. мы можем использовать функцию, даже если ей не предоставить никаких аргументов (скобки оставляем пустыми). Результат полученный функцией get_string (какой-то текст) будет помещен в переменную name.
Затем на следующей строке мы воспользуемся странным синтаксисом %s, чтобы включить в текст, который отобразится на экране, значение переменной. Если бы мы просто написали printf("hello, name\n"), на экране отобразилось бы hello, name. Но с %s мы можем добавить (или включить в текст) значение переменной name.
Теперь можно написать make string, а потом и ./string. Кажется что ничего не происходит. Программа просто ждет, что мы что-нибудь введем, а если быть точнее: она ждет текст (вы понимаете почему?). Давайте напишем David, нажмите enter и вы увидите, что она (программа) ответит вам hello, David, как и планировалось. Отлично!
Но давайте сделаем нашу программу немного понятнее. До того как мы попросим текст (string) от пользователя с помощью get_string, давайте сперва дадим ему понять, что мы от него хотим:
#include <cs50.h>
#include <stdio.h>
int main(void)
{
printf("Name: ");
string name = get_string();
printf("hello, %s\n", name);
}
И получится, что вводить данные пользователь будет сразу после текста Name:, в той же строке.
Шаг за шагом, строчка за строчкой, маленькими детскими шагами мы построили нашу простую программу и в общем это отличная техника написания любой программы. Делая так, мы будем проверять наш код на каждом этапе, чтобы убедиться что все работает, как нам нужно.
Давайте пойдем немного другим путем:
#include <cs50.h>
#include <stdio.h>
int main(void)
{
int i = get_int();
printf("hello, %i\n", i);
}
Теперь мы получаем целое число (integer), хранящаяся в переменной i, затем отдаем ее printf в виде %i, т.к. %s является заполнителем для текста (string), а i хранит в себе не string (текст), а integer (целое число).
Если мы скомпилируем, запустим и напишем David, программа нам скажет Retry (повторить попытку), пока мы не дадим ей (программе или, если быть еще точнее, функции get_int) число.
Эти первые примеры проведут нас (медленно, но с огромной пользой) через необходимые основы разработки, чтобы дальше мы могли создавать поистине потрясающие программы.
В действительности, Си позволяет нам получить еще больший контроль над процессами, происходящими в компьютере, и “смотреть под капот” (как код взаимодействует с железом) без каких-либо проблем.
Напишем другую короткую программу:
#include <cs50.h>
#include <stdio.h>
int main(void)
{
printf("x это ");
int x = get_int();
printf("y это ");
int y = get_int();
int z = x + y;
printf("суммой x и y будет %i\n", z);
}
Итак, мы получили от пользователя два числа, x и y, создали новую переменную z, которая хранит сумму двух чисел, и вывели результат на экран.
Но мы создали лишнее целое число, которое, на самом деле, можно просто пропустить:
#include <cs50.h>
#include <stdio.h>
int main(void)
{
printf("x это ");
int x = get_int();
printf("y это ");
int y = get_int();
printf("суммой x и y будет %i\n", x + y);
}
Немного математики:
#include <cs50.h>
#include <stdio.h>
int main(void)
{
printf("x это ");
int x = get_int();
printf("y это ");
int y = get_int();
printf("%i плюс %i будет %i\n", x, y, x + y);
printf("%i минус %i будет %i\n", x, y, x - y);
printf("%i умножить на %i будет %i\n", x, y, x * y);
printf("%i поделить на %i будет %i\n", x, y, x / y);
printf("остаток от деления %i на %i будет %i\n", x, y, x % y);
}
Обратите внимание на то, как мы реализуем все эти операции в Си. % дает нам остаток от деления первого числа на второе.
Что же мы ждем? Компилируем, запускаем и пишем 1 для x, после чего нажимаем Enter, далее 10 для y и опять Enter:
...
1 поделить на 10 будет 0
...
Все выглядит приемлемо кроме этой одной строки! Правильным ответом должен быть 0.1, не так ли? Но помните что мы работаем с integer‘ами (целыми числами) x и y, выводя их на экран и используя заполнитель %i, поэтому числа после запятой отбрасываются или вырезаются. (вместо 0.1 нам выдают 0.)
Мы можем исправить данный недочет, используя другой тип переменной под названием float, для числа с плавающей запятой (нецелое число):
#include <cs50.h>
#include <stdio.h>
int main(void)
{
printf("x это ");
float x = get_float();
printf("y это ");
float y = get_float();
printf("%f поделить на %f будет %f\n", x, y, x / y);
}
Теперь все правильно!
Типы Данных
Существует множество различных типов данных:
-
boolдля булевого значения (true или false / истина или ложь) -
charдля одного символа -
doubleдля крупного нецелого числа с бо́льшим количеством битов, чем у обычногоfloat -
float -
int -
long longдля крупного целого числа с бо́льшим количеством битов, чем у обычногоint -
string
Давайте напишем еще одну программу, чтобы показать сколько байтов выделяется под каждый из этих типов данных
#include <cs50.h>
#include <stdio.h>
int main(void)
{
printf("bool это %lu\n", sizeof(bool));
printf("char это %lu\n", sizeof(char));
printf("double это %lu\n", sizeof(double));
printf("float это %lu\n", sizeof(float));
printf("int это %lu\n", sizeof(int));
printf("long long это %lu\n", sizeof(long long));
printf("string это %lu\n", sizeof(string));
}
bool это 1
char это 1
double это 8
float это 4
int это 4
long long это 8
string это 8
Оказывается, если брать конкретно нашу систему Cloud9, bool будет занимать целый байт, char (character или символ) тоже возьмет 8 битов и т.д.
Но подождите, string (текст) не больше 8 байтов? Не волнуйтесь, совсем скоро мы расскажем вам как string может быть больше представленной величины.
Память в компьютере не может быть бесконечной и поэтому мы ограничены в количестве доступных байтов, поэтому мы можем хранить только ограниченное число цифр. К примеру представьте, что у нас есть бинарное число с 8 битами:
1 1 1 1 1 1 1 0
Если мы добавим к нему 1, то получим 1 1 1 1 1 1 1 1. Но что произойдет если мы добавим еще одну 1? Мы начнем переносить единицу над каждой цифрой пока не получим 0 0 0 0 0 0 0 0, но у нас не осталось слева битов чтобы там сохранить это большее число.
В программах такое поведение встречается при работе с integer‘ами:
#include <cs50.h>
#include <stdio.h>
int main(void)
{
int n = 1;
for (int i = 0; i < 64; i++)
{
printf("n это %i\n", n);
n = n * 2;
}
}
Мы знаем, что для int выделяется 4 байта или 32 бита, т.e. 2^32 возможных значений, это около 4 миллиардов значений. Но половина этих значений отрицательная, поэтому самое высокое положительное значение около 2 миллиардов.
В этой программе мы начинаем с n равного 1, каждый раз удваивая его:
n это 1
n это 2
n это 4
n это 8
...
n это 1073741824
n это -2147483648
n это 0
n это 0
...
Теперь мы знаем, что рано или поздно, если наше число будет только увеличиваться и станет больше размера выделенных для него битов, произойдет что-то ужасное. Этот “ужас” называют overflow (переполнение).
Мы можем поменять тип переменной n на long long и вывести его значение на экран, используя заполнитель %lld. Но, опять же, мы увидим, что дойдя до последнего шага - число “перевернется” и станет отрицательным.
В реальном мире, некоторые игры могут использовать integer‘ы для обозначения значений (чисел), порождая на свет безумных диктаторов !
Еще более серьезные баги (ошибки) могут дать нам выключающиеся самолеты.
Другой баг floating-point imprecision (неточность нецелых чисел, следующих после запятой). У float‘ов ограниченное количество битов. Но цифры следующие в числе после запятой - неограниченные, поэтому компьютеру приходится округлять и неточно отображать некоторые числа.
Давайте напишем программу, которая сможет нам это продемонстрировать:
#include <stdio.h>
int main(void)
{
printf("%.55f\n", 1.0 / 10.0);
}
Новая часть в коде %.55f просто говорит функции printf отобразить 55 чисел после запятой.
Мы использовали 1.0 и 10.0 только для того, чтобы удостоверится, что типы данных действительно будут float‘ами (так как мы не задали их как переменные). Мы могли бы написать (float) 10, чтобы изменить целое число 10 и превратить его в 10 с плавающей запятой (или точкой).
Запустим программу и получим:
0.100000000000000000555111512312578...
Интересно, оказывается так выглядит приблизительное представление компьютера, числа 0.1.
Вот клип о последствиях компьютерной неточности.
Давайте повторим - мы знаем, что есть несколько типов данных, которые мы имеем у себя в арсенале и можем представить (или отобразить в тексте) через символы (заполнители):
-
%c -
%f -
%d -
%i -
%lld -
%s -
…
В дополнение к \n, который служит для добавления новой строки, мы можем использовать определенные escape sequences (управляющие последовательности) или символы, которые применяются в printf для добавления в текст кавычек, табуляции и т.п.:
-
\a -
\n -
\r -
\t -
\' -
\" -
\\ -
\0 -
…
Больше Си
Напишем программу, в которой гораздо шире используются идеи Scratch’а, что позволит нам реализовать более сложные конструкции кода Си:
#include <cs50.h>
#include <stdio.h>
int main(void)
{
int i = get_int();
if (i < 0)
{
printf("отрицательное\n");
}
else if (i > 0)
{
printf("положительное\n");
}
else
{
printf("ноль\n");
}
}
Так как переменная i в последнем else (иначе) не больше и не меньше нуля, нам не нужно уточнять условие else if (i == 0), по логике отсюда вытекает, что переменная i будет равна нулю. Обратите внимание, что мы используем == для сравнения двух переменных или значений из-за того, что один знак = служит для присвоения одного значения другому.
Можем немного поиграться с логикой:
#include <cs50.h>
#include <stdio.h>
int main(void)
{
char c = get_char();
if (c == 'Y' || c == 'y')
{
printf("yes\n");
}
else if (c == 'N' || c == 'n')
{
printf("no\n");
}
else
{
printf("error\n");
}
}
Мы получаем от пользователя символ (character) c и сравниваем его либо с Y, либо с y или либо с N, либо с n. В Си мы используем || для указания логического или, где только одно из выражений должно быть истиной для выполнения условия. && для логического и, где оба выражения должны быть истиной, чтобы условие было выполнено.
Заметьте, мы используем одинарные кавычки вокруг символов, чтобы отличить их от текста (string), где есть только один символ и двойные кавычки соответственно.
Давайте по-другому создадим предыдущую программу:
#include <cs50.h>
#include <stdio.h>
int main(void)
{
char c = get_char();
switch (c)
{
case 'Y':
case 'y':
printf("yes\n");
break;
case 'N':
case 'n':
printf("no\n");
break;
default:
printf("error\n");
break;
}
}
Мы используем switch (переключатель), у которого есть различные случаи (case). Совпав с одним из них, переменная запустит выполнение кода, находящегося ниже случая (case‘а). И выполнение остановится только тогда, когда дойдет до выражения break; (остановить, сломать), который выведет нас из конструкции switch‘a (переключателя).
Удалим все строчки с break; выражениями и посмотрим что произойдет:
#include <cs50.h>
#include <stdio.h>
int main(void)
{
char c = get_char();
switch (c)
{
case 'Y':
case 'y':
printf("yes\n");
case 'N':
case 'n':
printf("no\n");
default:
printf("error\n");
}
}
И в этом случае (хе-хе), все выражения, находящиеся ниже первого совпавшего случая (case), будут выполнены.
Давайте посмотрим, как разрабатывать дизайн кода, создав свою функцию:
#include <cs50.h>
#include <stdio.h>
int main(void)
{
string s = get_string();
print_name(s);
}
void print_name(string name)
{
printf("hello, %s\n", name);
}
Заметьте, что ниже нашей функции main мы создали новую, назвав ее print_name. Эта функция принимает переменную с типом string (текст или строку) в виде параметра, к которому она будет в дальнейшем обращаться как к name. Никаких значений эта функция не возвращает, поэтому мы зададим ее тип возвращаемого значения как void (пустота/ничего). В то время как main возвращает значение с типом int. Потом еще поговорим на эту тему.
Но теперь, если мы скажем программе print_name(s) в нашей функции main, то мы все равно получим ошибку. Все это из-за того, что компилятор читает код сверху вниз, по порядку. Поэтому, когда main вызывает функцию print_name, она еще не существует для компилятора. Поэтому нам нужно объявить ее, используя prototype (прототип):
#include <cs50.h>
#include <stdio.h>
void print_name(string name);
int main(void)
{
string s = get_string();
print_name(s);
}
void print_name(string name)
{
printf("hello, %s\n", name);
}
Мы пишем над функцией main прототип void print_name(string name), указывая то, какие параметры она получит, а затем и вернет, для того чтобы компилятор поискал ее (функцию) немного позже.
И внутри наших библиотек cs50.h и stdio.h находятся точно такие же прототипы - однострочные выражения, объявляющие функции подобные get_string и printf с их имплементацией (implementation или реализацией) в другом файле.
Чтобы продемонстрировать возвращаемые значения, мы можем написать программу следующим образом:
#include <cs50.h>
#include <stdio.h>
int square(int n);
int main(void)
{
printf("x это ");
int x = get_int();
printf("x^2 это %i\n", square(x));
}
int square(int n)
{
return n * n;
}
Функция square принимает в виде параметра переменную типа int и возвращает что-то с типом данных int. Внутри функции выполняется только return n * n.
Теперь мы можем использовать функцию square(x) в нашей другой функции printf, которая будет ждать результат с типом данных int.
Если мы вернемся к нашей начальной функции get_string, мы можем кое-что понять. Например, что у функции get_string возможно есть прототип, который выглядит как-то так string get_string(void), так как она выполняется не принимая никаких параметров или аргументов (с пустыми скобками), но возвращает введенный пользователем текст:
#include <cs50.h>
#include <stdio.h>
int main(void)
{
string s = get_string();
printf("hello, %s\n", s);
}
Давайте немного улучшим наш блок cough, который мы создавали в Scratch’e на 0-ой неделе:
#include <stdio.h>
int main(void)
{
printf("cough\n");
printf("cough\n");
printf("cough\n");
}
Здесь мы пытаемся отобразить на экране текст cough три раза.
Итак, добавим в код цикл, т.к. у нас идет повтор одинаковых выражений:
#include <stdio.h>
int main(void)
{
for (int i = 0; i < 3; i++)
{
printf("cough\n");
}
}
Напишем нашу собственную функцию, чтобы использовать ее когда нам угодно, любое количество раз:
#include <stdio.h>
void cough(void);
int main(void)
{
for (int i = 0; i < 3; i++)
{
cough();
}
}
void cough(void)
{
printf("cough\n");
}
Кажется, что мы потратили излишне много усилий для создания данного примера, но чем сложнее будет становится наша программа, тем больше мы будем нуждаться в таких блоках и созданных нами функциях (custom functions).
К примеру, если бы мы хотели вызвать cough несколько раз, а еще и achoo определенное количество раз, то для нас это не должно составить никакого труда:
#include <cs50.h>
#include <stdio.h>
void cough(int n);
void say(string word, int n);
void achoo(int n);
int main(void)
{
cough(3);
achoo(3);
}
void cough(int n)
{
say("cough", n);
}
void say(string word, int n)
{
for (int i = 0; i < n; i++)
{
printf("%s\n", word);
}
}
void achoo(int n)
{
say("achoo", n);
}
Заметьте, что функция main может без труда вызвать cough и achoo определенное количество раз, указывая этот параметр в вызове каждой функции. Они же вызывают другую функцию say, которая содержит в себе реализацию цикла for и отображение текста на экране через printf.
Посмотрите на say - эта функция теперь тоже принимает два аргумента: один string (текст), а другой int (число). Поэтому каждый раз, когда вызывается эта функция, оба аргумента должны быть указаны.
Мы называем эту концепцию abstraction (абстракцией). В ней мы строим различные слои, в каждом из которых одновременно могут работать несколько людей, в итоге выполняя общую работу, где каждый человек реализовывает свою часть кода.
На самом деле, все это время мы пользовались абстракцией вызывая get_string или printf, т.к. мы знаем, как в действительности эти функции имплементированы (реализованы) в других файлах, которые мы включаем (задействуем). Теперь мы можем их использовать, зная их предназначение.
Давайте теперь посмотрим, чем же занимается make. Компиляция включает в себя несколько этапов.
препроцессирование (preprocessing)
- Строчки, которые начинаются с #, как например #include, препроцессируются. #include заставляет наш компилятор искать файл в нашем компьютере и буквально включить (include), или добавить, внутрь нашего кода строчки из препроцессируемого файла (т.е. скопировать и вставить все содержимое).
компиляция
- Мы пропишем команду
clang -S hello.cи увидим, как наша Си программа компилируется в другой язык (код), именуемый ассемблером. Он оснащен простыми инструкциями, которые понимает процессор или CPU (как например сложение чисел, их передвижение в памяти и т.д.). Они прописаны в текстовом формате, чтобы люди могли прочитать и изменить ход работы этих инструкций.
ассемблирование
- Промежуточный ассемблеровский код переводится в машинный код,
0и1, которые процессор действительно может понимать.
соединение
- Этот финальный шаг соединяет машинный код нашей программы и машинный код всех библиотек, которые мы ранее подключили и использовали. Соединяет их, в итоге выдавая нам финальную версию программы со всеми необходимыми кусочками кода. (Препроссированные через
#includeфайлы, представляют из себя заголовочные (header) файлы, которые содержат в себе только прототипы используемых нами функций. Настоящая имплементация, или реализация, в нашем случае уже машинного кода находится в других файлах.)
Итак, мы разобрали огромное количество новых концепций программирования, но будем надеяться, что со временем вы освоите то, что было приведено здесь и сможете легко их использовать!
В конце концов, вы сможете видеть в любой поставленной проблеме определенный шаблон действий, создавать дизайн кода и абстракции, для написания качественных программ.